Written by:
Slavé Petrovski
Vice President and Head of AstraZeneca's Centre for Genomics Research (CGR), Discovery Sciences, R&D
Earlier this year, it was announced that we now have access to the complete, gap-free human DNA sequence. It was a momentous achievement for the scientific community, and particularly exciting for researchers like me who use large-scale genetic data sets and cutting-edge analysis tools to explore the molecular bases of diseases. It’s a fascinating area, where our understanding grows every day. If we can discover the genes responsible for disease development and progression, then we’ll be better placed to identify at-risk patients earlier, and develop targeted and more effective treatments.
The goals of multi-omics
As part of our Genomics Initiative strategy, we continue to expand our genomics resources to capture greater genetic diversity, particularly focusing on regions of the globe that have historically been underrepresented in research. We are also expanding our multi-omics understanding by generating additional data on the same individuals where we already have rich data on their genomics and clinical outcomes. This both increases the efficiency of our research by allowing us to get from causal genetic biology to mechanistic understanding and systems biology considerably faster and also increases the confidence we have in our target science decision making milestones.
Here I summarise four recent publications from our Centre for Genomics Research (CGR), many achieved in close collaboration with our academic partners. These cover just a small part of the work we’re currently pursuing from pioneering best practices, to developing novel advanced analytical methods, to discovering novel drug targets and disease pathways that could be the clues to tomorrow’s medicines and Precision Medicine strategies.
Great learnings from expanding banks of data
So, what’s driving our new understanding of genes and the role they play in disease? Our genomics knowledge has grown exponentially in recent years due to the increased availability of sequencing data from large populations with linked electronic health records. These vast data sets need to be explored to find the key genetic links between diseases that present with similar clinical features but are driven by different molecular mechanisms. It’s no easy feat and scale is critical – this is why we set an ambitious goal to analyse up to two million genomes by 2026. Our Genomics Initiative is already providing novel insights into disease biology and helping us uncover new rare gene variants and potential drug targets for future medicines.

The UK Biobank is one of the greatest resources for medical researchers. Every individual within the Biobank is the ‘genetic result’ of many generations – each impacted by selective forces, adaptation to new environments and random gene mutations.
Using the UK Biobank, we can sample hundreds of thousands of individuals and match their genetic profiles to tens of thousands of health outcomes through electronic health records, self-reported outcomes, imaging, biochemistry, and much more. It has opened up genomics and medical research like never before.
Data sets from the UK Biobank and other more recent and genetically diverse populations have allowed my colleagues and I, in our CGR, to make important progress in mapping the genetic causes of a range of diseases. In August 2021, we published a milestone UK Biobank sequencing paper in Nature, which offered new insights on the causal biology of some common diseases, helping to accelerate the identification of novel therapeutic targets that are validated by human genetics.1 More recently, our CGR has published three further high-impact papers that advance our understanding of genomics and offer new knowledge on why some people may be more susceptible to certain chronic diseases than others.
Exposing the impact of clonal haematopoiesis
Clonal haematopoiesis (CH) – when a haematopoietic stem cell replicates with the same genetic mutation – is one of the most extensively studied cellular mutations. The spontaneous mutations that occur are known to be linked to ageing, yet little is known about the causes, biological basis and implications of CH.2
Our new research published in Nature Genetics used a genome-wide analysis of 421,000 individuals from the UK Biobank to dig into the genetic basis of CH. It provided important new disease insights, identifying several gene variants and multiple new germline loci associated with increased risk of CH. It also revealed that smoking and longer telomere length are both causal risk factors for developing CH later in life.3
Our next research goal is to identify how these genetic mutations may predict chronic disease development, particularly inflammatory diseases. Our research showed that a genetic predisposition to CH increased a person’s risk of developing blood cancers, such as myeloproliferative neoplasia (a rare disorder of the bone marrow), non-haematological malignancies, cardiovascular diseases such as atrial fibrillation (irregular heartbeat), as well as encouraging premature ageing.3

By expanding our knowledge of the molecular drivers behind these CH genetic mutations, we hope to identify individuals predisposed to chronic diseases and advance understanding of how inflammatory mechanisms (inflammasomes) can manifest into disease.
This is the largest systematic study of the genetics of clonal haematopoiesis to date. It enhances our understanding of the basis for the inherited susceptibility to the phenomenon and provides new insights into its pathogenesis and its consequences for human health and ageing. We’re at the beginning of our journey of scientific discovery with much more to learn about the genetic mechanisms driving clonal haematopoiesis and the role that precision medicine strategies might play in preventing its adverse effects on human health.
New genetic clues to the life-threatening lung disease idiopathic pulmonary fibrosis

Image Source: Arch Pathol Lab Med.2012;136(6):591–600. Image courtesy of Richard Webb, MD.
Another area of considerable unmet need that we are actively exploring with genomics is idiopathic pulmonary fibrosis (IPF), a chronic, progressive lung disease which leads to scarring (fibrosis) of the lungs, respiratory failure and death.4
For many years the scientific community has sought to better understand this life-threatening disease. Despite considerable research effort, there are sadly few treatment options currently available to patients and these only slow disease progression rather than ultimately changing long-term prognosis.
Our latest research published in the American Journal of Respiratory and Critical Care Medicine provides a new clue to the potential genetic causes of IPF. Reduced expression of the KIF15 gene has previously been shown to be linked to a range of different types of fibrotic interstitial lung diseases.5
Our research confirmed that both rare and common genetic variants in the KIF15 gene increased a person’s susceptibility to IPF by decreasing KIF15 protein expression and reducing cell proliferation. Additionally, the research further highlights our previous finding of a novel mechanism that we believe could underlie IPF in some patients, expanding on our discoveries of the IPF genes SPDL1 (Spindly) and TERT, and providing potential new avenues for exploration.6,7
This is the largest exome sequencing to have been undertaken in IPF, helping researchers to identify novel gene targets and discover potential drug candidates that may address new disease pathways. Understanding the underlying biology of IPF may be the key to improving patient outcomes and extending life expectancy in this disease of significant unmet need.
Hunting genes by leveraging ‘biomarker fingerprint’ similarity
Genes with shared biomarker patterns often behave in similar ways and may have a comparable impact on human disease. This can be extremely helpful for researchers when conducting drug discovery experiments, especially if certain genes are deemed ‘difficult to target’ or ‘undruggable’.
Our CGR has developed a novel tool called Gene-SCOUT (Gene-Similarity from COntinUous Traits) which draws on data from 500,000 human sequences to identify genes with similar associations based on their shared biomarker profiles. Findings recently published in Nucleic Acids Research revealed that this novel tool can more accurately find genes with similar clinical traits versus existing methods.8
Gene-SCOUT is opening up new possibilities for genetic research, helping scientists to identify other genes with comparable characteristics that may be more suitable targets for drug development.
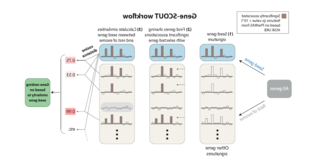
Source: Middleton L, et al. Nucleic Acids Research. 2022;50:4289-4301.
To help progress disease understanding and drug discovery across the globe, it’s essential that we continue to collaborate and share our scientific learnings. As part of this commitment, we have made Gene-SCOUT freely available as a web resource, helping drive scientific exploration even in places where the infrastructure and resources may not enable large scale genome analysis to be undertaken. Enhancing genomic understanding together will help to make the greatest and most rapid global impact on disease.
We are applying artificial intelligence and machine learning together with genomics to answer some of the trickiest medical questions. Gene-SCOUT is an elaborate and much more accurate way of validating gene fingerprints which has important implications for our precision medicine strategies. If we can better understand underlying and interconnected disease biology, we may be able to identify alternative target opportunities for genes of interest, broadening future therapeutic possibilities.
Using genomics and Precision Medicine to innovate R&D
Exciting times lie ahead! We are digging deep into the biology of complex chronic diseases, using vast networks of genomic data to explore and uncover novel insights. With this knowledge, we will be better equipped to identify individuals at risk of developing certain diseases, earlier, and to discover important new treatments in the future.
Genomics is now an integral part of our R&D, and over 90% of our pipeline uses a precision medicine approach. By making human genetics central to our drug discovery, we hope to accelerate development, and ultimately improve the quality of therapies and outcomes for patients.